
本文通过编写一个通用的片段着色器,实现了抖音中的各种分屏滤镜。另外,还讲解了延时动态分屏滤镜的实现。
一、静态分屏
静态分屏指的是,每一个屏的图像都完全一样。
分屏滤镜实现起来比较容易,无非是在片段着色器中,修改纹理坐标和纹理的对应关系。分屏之后,每个屏内纹理的对应关系都不太一样。因此在实现的时候,容易写的很复杂,会有大量的区域判断逻辑。
这样实现出来的着色器拓展性比较差。假如有多种分屏滤镜,就要实现多个着色器,而且屏数越多,区域判断逻辑就越复杂。
所以,我们会采取一种更优雅的方式,为所有的分屏滤镜实现一个通用的着色器,然后将屏数当作参数,由着色器外部控制。
预备知识
首先,我们来了解等一下会使用到的 GLSL 运算和函数。vec2 是二维向量类型,它支持下面的各种运算。
1、向量与向量的加减乘除(两个向量需要保证维数相同)
下面以乘法为例,其他类似。
1 | vec2 a, b, c; |
等价于
1 | c.x = a.x * b.x; |
2、向量与标量的加减乘除
下面以加法为例,其他类似。
1 | vec2 a, b; |
等价于
1 | b.x = a.x + c; |
3、向量与向量的 mod 运算(两个向量需要保证维数相同)
1 | vec2 a, b, c; |
等价于
1 | c.x = mod(a.x, b.x); |
4、向量与标量的 mod 运算
1 | vec2 a, b; |
等价于
1 | b.x = mod(a.x, c); |
着色器实现
有了上面的 GLSL 运算知识,来看下我们最终实现的片段着色器。
1 | precision highp float; |
(1) 我们最终暴露的接口,通过 uniform 变量的形式,从着色器外部传入横向分屏数 horizontal 和纵向分屏数 vertical 。
(2) 开始运算前,做了最小分屏数的限制,避免小于 1.0 的分屏数出现。
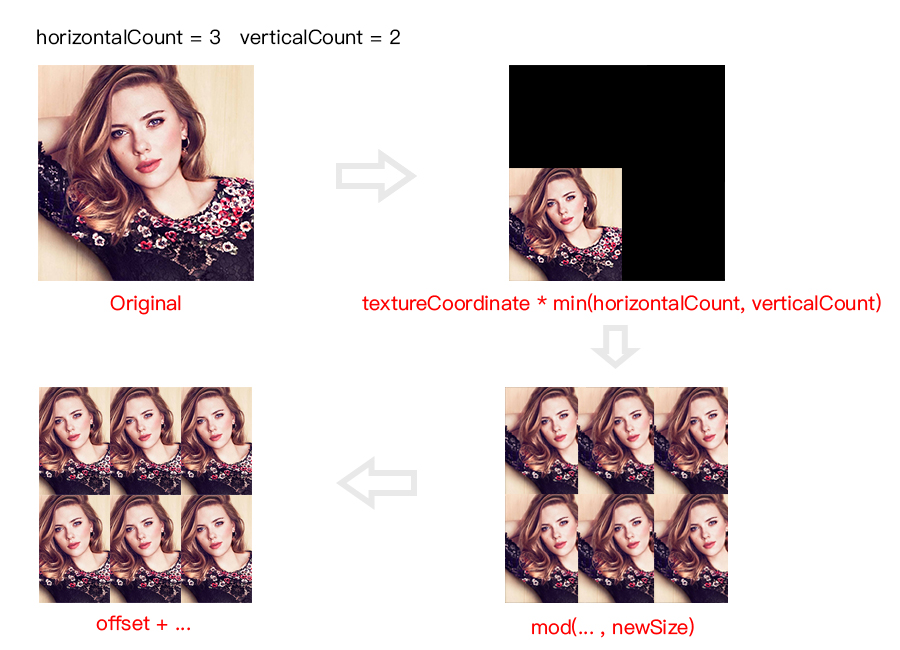
(3) 从这一行开始,是为了计算分屏之后,每一屏的新尺寸。比如分成 2 : 2,则 newSize 仍然是 (1.0, 1.0),因为每一屏都能显示完整的图像;而分成 3 : 2(横向 3 屏,纵向 2 屏),则 newSize 将会是 (2.0 / 3.0, 1.0),因为每一屏的纵向能显示完整的图像,而横向只能显示 2 / 3 的图像。
(4) 计算新的图像在原始图像中的偏移量。因为我们的图像要居中裁剪,所以要计算出裁剪后的偏移。比如 (2.0 / 3.0, 1.0) 的图像,对应的 offset 是 (1.0 / 6.0, 0.0) 。
(5) 这一行是这个着色器的精华所在,可能不太好理解。我们将原始的纹理坐标,乘上 horizontalCount 和 verticalCount 的较小者,然后对新的尺寸进行求模运算。这样,当原始纹理坐标在 0 ~ 1 的范围内增长时,可以让新的纹理坐标在 newSize 的范围内循环多次。另外,计算的结果加上 offset,可以让新的纹理坐标偏移到居中的位置。
下面简单演示一下每一步计算的效果,帮助理解:
(6) 通过新的计算出来的纹理坐标,从纹理中读出相应的颜色值输出。
效果展示
现在,我们得到了一个通用的分屏着色器,像三屏、六屏、九屏这些效果,只需要修改两个参数就可以实现。另外,上面的实现逻辑,甚至可以支持 1.5 : 2.5 这种非整数的分屏操作。

二、动态分屏
动态分屏指的是,每个屏的图像都不一样,每间隔一段时间,会主动捕获一个新的图像。
由于每个屏的图像都不一样,因此在渲染过程中,需要捕获多个不同的纹理。比如我们想要实现一个四屏的滤镜,就需要捕获 4 个不同的纹理。
预备知识
我们知道,在 GPUImage 框架中,滤镜效果的渲染发生在 GPUImageFilter 中。
从渲染层面来说,GPUImageFilter 接收一个纹理的输入,然后经过自身效果的渲染,输出一个新的纹理 。
但实际上,由于渲染过程需要先绑定帧缓存,所以纹理被包装在 GPUImageFramebuffer 中。
因此,在不同的 GPUImageFilter 之间传递的对象其实是 GPUImageFramebuffer。一般的流程是,从 firstInputFramebuffer 中读取纹理,将结果渲染到 outputFramebuffer 的纹理中,然后将 outputFramebuffer 传递给下一个节点。
而 outputFramebuffer 是需要重新创建的,如果不做额外的缓存处理,在整个滤镜链的渲染中,将需要创建大量的 GPUImageFramebuffer 对象。
因此, GPUImage 框架提供了 GPUImageFramebufferCache 来管理 GPUImageFramebuffer 的重用。当需要创建 outputFramebuffer 的时候,会先从 GPUImageFramebufferCache 中去获取缓存的对象,获取不到才会重新创建。
由于纹理被包装在 GPUImageFramebuffer 中,所以当 GPUImageFramebuffer 被重用时,原先保存的纹理就会被覆盖。
GPUImageFramebuffer 提供了 lock 和 unlock 的操作。 lock 会使引用计数加 1,unlock 会使引用计数减 1,当引用计数为 0 的时候,GPUImageFramebuffer 会被加入到 cache 中,等待被重用。
所以,我们要捕获纹理,做法就是:在拍摄过程中,不让 GPUImageFramebuffer 进入 cache。
注: 这里的引用计数不是 OC 层面的引用计数,而是
GPUImageFramebuffer内部的一个属性,属于业务逻辑层的东西。
代码实现
1、捕获和释放
GPUImageFramebuffer 的捕获和释放都很简单,通过 lock 和 unlock 来实现,
1 | [firstInputFramebuffer lock]; |
1 | [self.firstFramebuffer unlock]; |
2、多纹理的渲染
在捕获了额外的纹理后,需要重写 -renderToTextureWithVertices:textureCoordinates: 方法,在里面传递多个纹理到着色器中。
1 | // 第一个纹理 |
同时在着色器中接收并处理:
1 | precision highp float; |
由于这里每个屏接收的纹理都不一样,就不可避免地要添加区域判断逻辑了。
效果展示
最后,看一下延时动态分屏的效果:

源码
请到 GitHub 上查看完整代码。